Mejorar la detección de spam con SpamAssassin.
Spamassassin es bastante bueno detectando correo basura, pero hoy vamos a configurarlo para hacerlo el mejor.

Apache SpamAssassin es la primera línea de defensa contra el correo no deseado entre el servidor y nuestros clientes de correo electrónicos. Por defecto el sistema reconoce bastante bien los patrones de spam pero mediante la enseñanza personalizada podemos hacerlo muchísimo mejor. Para comenzar esta guía vamos a utilizar como base un servidor Centos7 instalado y funcionando con VestaCP y SpamAssassin 3.4.0. Para verificar la versión ingresamos
spamassassin -V
SpamAssassin version 3.4.0
running on Perl version 5.16.3
Lo primero es verificar que todo esté funcionando correctamente:
spamassassin -D --lint 2>&1 | grep -i failed
En nuestras instancias de VestaCP encontramos siempre los mismos errores
dbg: diag: [...] module not installed: Digest::SHA1 ('require' failed)
dbg: diag: [...] module not installed: Razor2::Client::Agent ('require' failed)
dbg: diag: [...] module not installed: Net::Patricia ('require' failed)
Estos mensajes indican que faltan instalar los módulos de Perl SHA1, Net-Patricia y el Razor-Agent. Para instalar los plugins faltantes ejecutamos (es necesario tener EPEL instalado):
yum install perl-Digest-SHA1 perl-Net-Patricia perl-Razor-Agent
Una vez instalados reiniciamos el servicio
service spamassassin restart
Y volvemos a verificar que esté todo correcto
spamassassin -D --lint 2>&1 | grep -i failed

Comienza el entrenamiento.
SpamAssassin utiliza un clasificador Bayesiano para tratar de identificar el spam.
En teoría de la probabilidad y minería de datos, un clasificador Bayesiano ingenuo es un clasificador probabilístico fundamentado en el teorema de Bayes y algunas hipótesis simplificadoras adicionales. Es a causa de estas simplificaciones, que se suelen resumir en la hipótesis de independencia entre las variables predictoras, que recibe el apelativo de ingenuo.
Éste clasificador lo que hace es recolectar tokens, que son palabras o secuencias de caracteres que son comunes a los correos no deseados (spam) o los correos legítimos (ham). La pregunta ahora es ¿a partir de qué datos va a determinar si es spam o ham?. La respuesta: nuestros correos.
Hay varias maneras de que SpamAssassin aprenda, las más comunes son
- Aprendizaje sin supervisión con reglas de SA (
auto-learning). El clasificador aprende de las propias reglas internas de filtrado. - Supervisado. El clasificador aprende de mails previamente clasificados por el usuario como spam y ham.
La ventaja del entrenamiento sin supervisión es que (lógicamente) no requiere trabajo extra del usuario. Por otro lado, la tasa de éxito de detección de spam/ham puede ser menor que el supervisado. Entonces lo mejor es iniciar el entrenamiento con mails que ya hayamos marcado como spam y luego con la cantidad de datos suficientes pasemos al modelo de auto-learning.
Paso 1: Recolección de muestras.
Nosotros utilizamos Thunderbird para realizar este trabajo preliminar. La estrategia es tener una carpeta llamada SPAM, en una de las cuentas, con todos los mails que manualmente marcamos como spam para entrenar al propio clasificador Bayesiano de Thunderbird y luego utilizar esas muestras para entrenar a SpamAssassin.
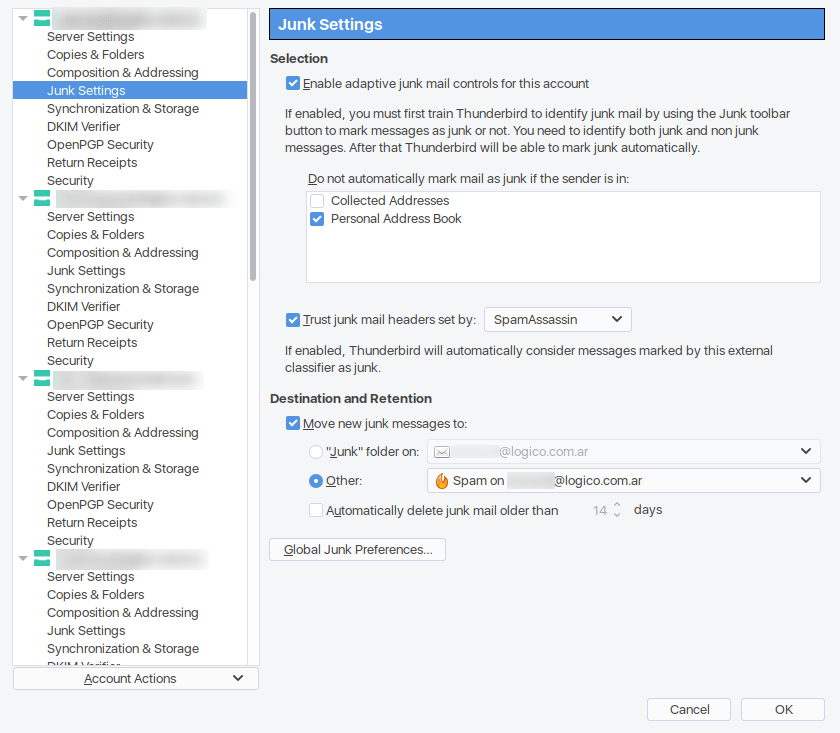
Para activar el filtro de Thunderbird hay que ir a Menú > Opciones > Configuración de cuenta y activar las opciones:
- Activar control adaptativos de correo no deseado para esta cuenta.
- Confiar en las cabeceras de correo no deseado enviadas por SpamAssassin. ⚠️ IMPORTANTE.
- Mover nuevos mensajes de correo no deseado a:, seleccionar Otra y luego seleccionar la carpeta
SPAM.
En nuestro caso, en los puestos que tienen varias cuentas configuradas, movemos todos los correos de spam a una única carpeta SPAM de una sola cuenta de correo. De esta manera es más fácil tener todos los correos no deseados en un solo lugar. Una vez que esté todo configurado y los correos clasificados procedemos al entrenamiento de SpamAssassin.
Paso 2: Pasando conocimiento con sa-learn.
El comando sa-learn nos permite ingresar la data recolectada al clasificador Bayesiano de SpamAssassin. Es recomendable tener una buena cantidad de correos clasificados para iniciar el entrenamiento. Nosotros comenzamos con una muestra de 2000 correos no deseados y 8000 legítimos. Entonces, para empezar el entrenamiento de spam:
sa-learn --spam /home/USER/mail/DOMINIO/CUENTA/.Spam/
Ahora sólo falta enseñarle cuales son los patrones de correos legítimos. Para ello se utiliza el comando
sa-learn --ham /home/USER/mail/DOMINIO/CUENTA/.CARPETA/
Si hay varias (muy probablemente) carpetas/cuentas de que queremos utilizar como muestra, podemos utilizar un archivo con la lista de directorios. Una manera para generarla puede ser:
ls -d /home/USER/mail/DOMINIO/CUENTA/.?* >> ~/HAM
Tendríamos que editar el archivo para quitar las carpetas .. y las que contengan spam y finalmente podemos volver a entrenar el clasificador con:
sa-learn --ham -f ~/HAM
Paso 3: Puesta en marcha.
Una vez realizado el entrenamiento, verificamos que SA haya aprendido con el comando:
sa-learn --dump magic
Los datos más importantes son
0.000 0 1027 0 non-token data: nspam
0.000 0 6010 0 non-token data: nham
nspam es la cantidad de tokens identificados como spam y nham la cantidad para ham.
Para activar el filtrado hay que editar el archivo /etc/mail/spamassassin/local.cf y agregar las líneas
use_bayes 1
bayes_auto_learn 1
use_bayes 1indica que tiene que usar el clasificador Bayesiano.use_bayes 1indica que tiene que usar el auto aprendizaje.
Finalmente reiniciar el servicio y verificar que todo está bien
service spamassassin restart
spamassassin -D --lint 2>&1 | grep -i failed